原文链接:https://www.chenweiliang.com/cwl-29315.html
百度Spider抓取诊断异常信息: socket读写错误怎么办?
假设你的网站一直都没有被百度收录,首先要在百度搜索资源平台进行蜘蛛抓取诊断。
百度爬虫抓取诊断链接失败怎么办?
如果百度爬虫抓取诊断好几次都失败,防火墙可能已经阻止了爬虫程序。
百度搜索资源平台 > 抓取诊断 > 抓取异常信息: socket 读写错误 ▼

- 尤其是使用Cloudflare CDN的时候,默认是屏蔽的。
- 在互联网上,有说要添加IP 地址
xxx.xxx.xxx.xxx/24 - 然而,尝试了无效。
我没有在服务器上拦截百度蜘蛛,所以问题应该是Cloudflare的WAF!
登录Cloudflare → 安全性 → WAF → 防火墙规则 → 创建防火墙规则
- 在Cloudflare上查找与爬虫相关的WAF规则,发现了“合法机器人爬虫”选项 ▼

在Cloudflare上查找与爬虫相关的WAF规则,发现了“合法机器人爬虫”选项"/>
- 创建防火墙规则后,等待10分钟,然后抓取诊断,果然全部成功抓取到!
百度爬虫Sitemap抓取失败、连接超时怎么回事?
如果在百度搜索资源平台提交Sitemap文件地址,出现抓取失败、连接超时的问题 ▼

百度爬虫抓取Sitemap地图失败解决方案
登录Cloudflare → 安全性 → WAF → 防火墙规则 → 创建防火墙规则 ▼
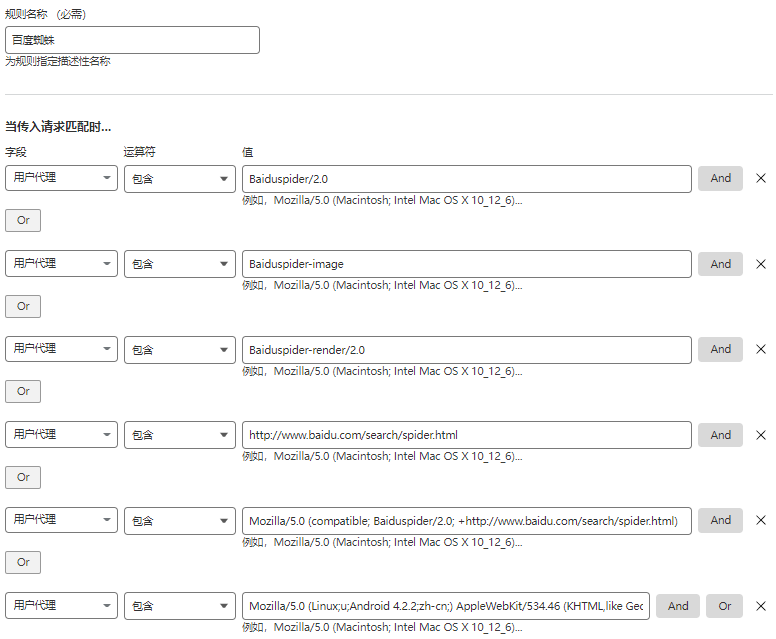
- 字段,选择“用户代理”
- 运算符,选择“包含”
- 添加新的用户代理,点击最后的“Or”
- 值,分别输入以下百度蜘蛛UA用户代理:
-
Baiduspider/2.0 -
Baiduspider-image -
Baiduspider-render/2.0 -
http://www.baidu.com/search/spider.html -
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) -
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
完成后再次测试取,结果返回HTTP头200,表示抓取成功 ▼
-
抓取诊断 > 抓取详情以下是百度Spider抓取结果及页面信息: -
提交网址: https://www.etufo.org/sitemap_baidu.xml -
抓取网址: https://www.etufo.org/sitemap_baidu.xml -
抓取UA: Mozilla/5.0 (compatible; Baiduspider/2.0; -
+http://www.baidu.com/search/spider.html) -
抓取时间: 2022-11-11 19:03:44 -
网站IP: 172.***.***.149 -
下载时长: 0.868秒 -
返回HTTP头:HTTP/2 200
其它蜘蛛和爬虫的用户代理,也可以用同样的方法自行搜索。
希望陈沩亮博客( https://www.chenweiliang.com/ ) 分享的《》,对您有帮助。
欢迎加入陈沩亮博客的 Telegram 频道,获取最新更新!
喜欢就分享和按赞!
您的分享和按赞,是我们持续的动力!
欢迎转载《百度蜘蛛抓取失败诊断异常信息socket读写错误连接超时怎么办》
欢迎分享本文链接:https://www.chenweiliang.com/cwl-29315.html
网站地址:https://www.chenweiliang.com/
欲获取更多资讯内幕和秘技,欢迎进入Telegram频道:https://www.chenweiliang.com/go/tgchannel
没有评论:
发表评论